Predicción del mercado de acciones
Tabla de Contenido
Introducción
La automatización de los mercados ha revolucionado el mercado de valores en las últimas décadas. Según estudios de 2014 más del 75% de las transacciones realizadas en las bolsas de USA fueron realizadas a través de sistemas automatizados, y se cree que desde ese año la tendencia no ha hecho más que aumentar.
Las ventajas de la automatización son varias e indiscutibles1:
- Minimiza la influencia de las emmociones humanas en las transacciones
- Existe la posibilidad de probar de forma automatizada diferentes estrategias utilizando información del pasado para seleccionar la más óptima para cada asset
- Se mejora la velocidad de reacción, ejecutando la transacción en el momento óptimo, sin dejar pasar oportuindades.
Inicialmente el sistema tomaba decisiones basadas en reglas configuradas por los usuarios. Posteriormente fueron creciendo en popularidad los market advisors, que en base a análisis técnico clásico de indicadores y tendencias, junto con reglas preconfiguradas, proveían a los sistemas de triggers de compra y venta. Con el advenimiento de las nuevas tecnologías en IA y análisis de sentimiento, comenzaron a tenerse en cuenta nuevos factores a la hora de desarrollar market advisors.
Los market advisors sustentados en IA y análsis de sentimiento ha llegado a topes de 80% de fiabilidad según anuncian algunos fabricantes de software2. Y es que si bien, según los especialistas se cree imposible que una máquina sea capaz de predecir completamente el mercado, por tratarse de un sistema con información muy ruidosa, aleatoria y donde entran en juego factores demasiado diversos3, la predicción del mercado de valores es un problema en el que logrando un 51% de aciertos ya es posible obtener ganancias.
A día de hoy, la información de las bolsas de valores es accesible de forma gratuita y en tiempo real a través de diversas API de terceros. Los sistemas de IA son relativamente fáciles de construir con fines experimentales, delegando la carga computacional a servidores en la nube.
Con estos factores en cuenta, es que se emprende el presente proyecto buscando lograr la construcción de un sistema basado en inteligencia artificial para predecir los movimientos del mercado de valores.
Metodología
Objetivo
Transitar todas las etapas de CRISP DM para desarrollar un sistema que permita predecir, con al menos un 51% de confiabilidad, los movimientos de precio de un determinado asset. A partir de esas predicciones generar señales de compra y venta para obtener ganancias.
Entendiendo el negocio
Entendiendo los datos
Los datos con los que se trabajará será un histórico de precios. Por tratarse de información fechada, ordenada en el tiempo, se trata entonces de un conjunto de datos de Time Series o Serie Temporal. Todo el tratamiento que se lleve a cabo tendrá que tener esto en cuenta, ya que hay una relación muy estrecha entre un elemento de la muestra y el siguiente en el tiempo.
Para este problema se obtendrá información desde el primer día de cotización pública del asset hasta la actualidad, tomando muestras diarias.
Obtención de los datos financieros
Si bien se necesita datos hisotóricos, también se va a necesitar información actualizada al día para poder hacer buenas predicciones para el futuro cercano. Es por esto que se opta por utilizar un servicio que provea tanto información del pasado como información actual y que provea los datos en una interface manejable con facilidad por las herramientas elegidas.
El servicio elegido será el de Yahoo Finance, reconocido sitio de información financiera y que cumple con los requisitos buscados. El acceso a su información será hecho a través de la biblioteca de python yfinance que convierte la información de Yahoo en dataframes de Panda.
RapidMiner tiene un componente para ejecutar scripts de python y obtener como resultado de los mismos un dataframe de Panda. Será entonces utilizado como Data Source de RapidMiner un script python que, utilizando yfinance colecte la información histórica desde Yahoo Finance y la ponga a dispocición de RapidMiner para ser procesada.
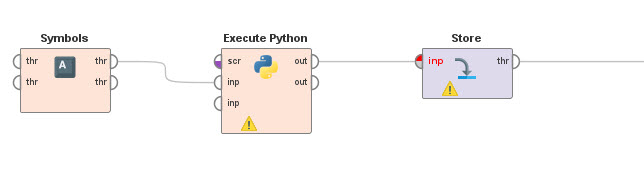
El script python escrito recibe una lista de símbolos (identificadores de cada asset), obtiene la información de cada uno desde Yahoo Finance y hace un join por fecha.
Datos obtenidos
Yahoo Finance devuelve la siguiente información histórica de cada uno de los símbolos:
| Feature | Descripción |
|---|---|
| Date | Fecha de los datos. Índice de la columna. |
| Open | Primera cotización del día, en dólares. |
| Close | Última cotización del día, en dólares. |
| Low | Cotización mínima del día, en dólares. |
| High | Cotización máxima del día, en dólares. |
| Volume | La cantidad total de assets que fueron comerciados. |
| Dividends | Si ese día el asset pagó dividendos y cuánto. |
| Stock Splits | Si se produjo un split en el valor de la acción. |
En caso de seleccionarse más de un asset del que obteneer información histórica, se concatenan las mismas columnas con la información correspondiente a cada asset.

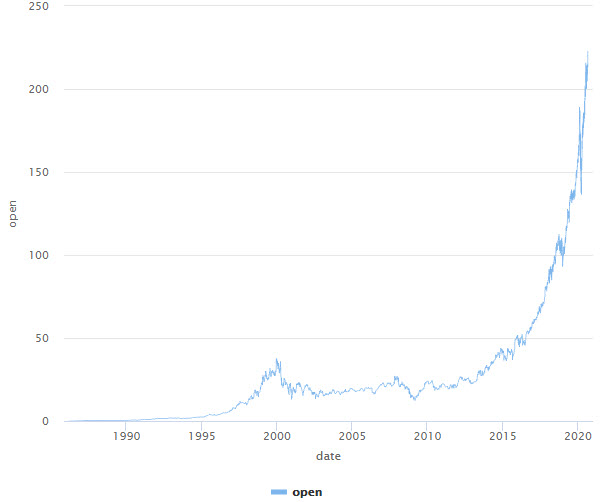
Se observa que la información obtenida no contiene valores faltantes, ni se observan outliers.
Preparando los datos
Indicadores estándar
El entrenamiento de los sistemas de inteligencia artificial se realiza con cada elemento de la muestra de forma independiente de los demás. Para que el motor pueda utilizar la información implícita en la serie temporal (tendencias, patrones, estacionalidades, etc.) será necesario agregar nuevas features que codifiquen esta información de una forma útil.
Se utilizará la biblioteca de python stockstats para generar indicadores estándar, que son utilizados tradicionalmente para el análisis técnico de las fluctuaciones de mercado. Esto va a permitir correlacionar la información puntual de un día con los días pasados en distintas escalas, estudiando distintos componentes de las fluctuaciones.
Los indicadores que se utilizarán serán los siguientes:
| Indicadores | Descripción |
|---|---|
| CR | Promedio del impulso de compra en los últimos 5, 10 y 20 días móviles. |
| KDJ | Una forma del oscilador estocástico4 a 9 días. |
| SMA | Media móvil simple de los últimos 2 días. |
| MACD | Media móvil de convergencia/divergencia configurado como (12,26,9) días. |
| Bollinger Bands | Bandas de Bollinger. |
| RSI | Índice de fuerza relativa a 6 y 12 días. |
| WR | Indicador de impulso Williams %R a 10 y 6 días. |
| TR y ATR | Rango Verdadero, indicador de volatilidad. |
| DMA | Diferencia de la media móvil promediada a largo plazo, entre 10 y 50 días |
| TR y ATR | Rango Verdadero, indicador de volatilidad. |
Los parámetros en días son los valores por defecto de la biblioteca, pero además son los valores estándar utilizados para el análisis tradicional. Eventualmente podrían modificarse para optimizar las predicciones. Asimismo es posible que varios de estos cálculos resulten mantener una correlación muy alta con el valor que se desea calcular, por lo que es posible que se descarten por correlación.
Estos indicadores serán calculados en el script python de obtención de datos, y quedarán disponibles en el dataset para ser manipulado en rapidminer.
Como algunos indicadores hacen uso de hasta 60 días hacia atrás, se excluyen de los datos los primeros 60 días para evitar datos faltantes en esos días para esos indicadores.
Columna objetivo
Se desea predecir el precio promedio que va a tener el asset en el futuro. Para esto se va a crear una nueva columna que sea el promedio en entre Low y High, el máximo y el mínimo de cada día.
Diferenciación y normalización
El precio de los assets, por lo general, muestra una tendencia alcista, desde números muy pequeños al inicio a números muy altos al final, lo que dificulta el estudio de estacionalidades.
Para evitar este problema, se estudiará el valor diferencial, lo que permitirá ver la velocidad de crecimiento y no el crecimiento en sí. Para realizar esta operación se utilizará el bloque Differentiate del paquete TimeSeries de RapidMiner y se agregarán dos columnas: una con la variación neta en el precio y otra con un porcentaje, indicando la variación relativa, siempre con respecto al día anterior.
Extracción de la fecha
Se extrae de la fecha los siguientes datos que usualmente participan en la estacionalidad de los movimientos del mercado: mes del año, cuatrimestre del año, día de la semana y día del mes.
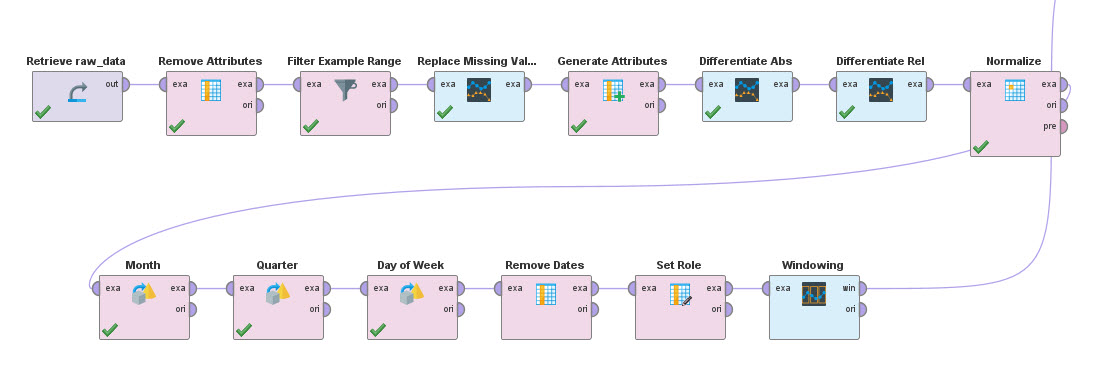
Ventanas
Cada día (fila) de los datos obtenidos no es un sample independiente, sino que guarda una estrecha relación con lo sucedido en días anteriores. Para que al alimentar el modelo esta información sea tenida en cuenta será necesario agregar a cada sample la información de los días anteriores como features nuevos. Este procedimiento está previsto en RapidMiner y se logra utilizando el bloque Windowing. De esta forma, para cada fila se agreaga información de las filas anteriores.
El bloque Windowing agrega además una nueva columna, “horizon”, a partir de nuestra anterior columna objetivo “avg”, que será la columna objetivo a predecir. Este valor corresponde al “valor de mañana” y servirá para entrenar al modelo a predecir valores futuros.
Es decir, el modelo será capaz de, teniendo todos los valores de los indicadores correspondientes a hoy y a los días previos, poder predecir el valor del cambio en el precio promedio para el día de mañana.
Modelado
Reducción de predictores
Será hecho un análisis de componentes principales para reducir la cantidad de predictores, que luego de la operación de ventanas, quedó en un número muy elevado: 3622. De esta forma los modelos podrán entrenarse de forma más rápida y se podrá hacer un acercamiento más veloz a la exactitud que se pueda obtener.
Tras ejecutar el análisis de componentes principales, la cantidad de predictores se redujo a 95.
Métodos tradicionales
La literatura sobre el tema habla de que los métodos tradicionales de predicción no obtienen buenos resultados debido a la irregularidad casi que aleatoria que gobierna los mercados. Sin embargo, como primer acercamiento se decide utilizar Random Forest, Decision Tree y Generalized Linear Model. La exactitud obtenida se muestra a continuación:
Redes neuronales recurrente
Para la predicción de series temporales, la literatura recomienda la utilización de Redes neuronales recurrentes5. En particular las llamadas redes Long Short-Term Memory (LSTM).
Las redes LSTM se especializan en crear dependencias entre los datos de entrenamiento, de forma que por ejemplo, en una serie temporal, cada dato de entrenamiento posterior tiene una relación especial con los previamente entrenados. De esta forma la información de un día tiene mantiene estrechas relaciones con la de los días anteriores, por lo que el entrenamiento y la predicción tendrá esto en cuenta6.
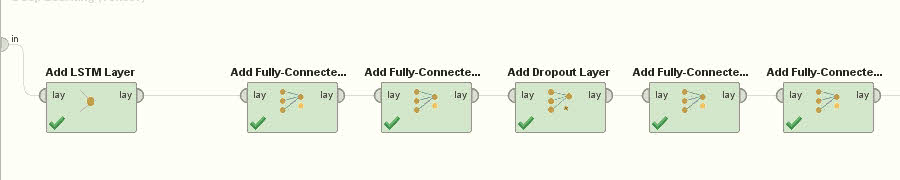
Para integrar LSTM se utilizará la extensión de RapidMiner “Redes Neuronales”, que permite la creación de una red LSTM.
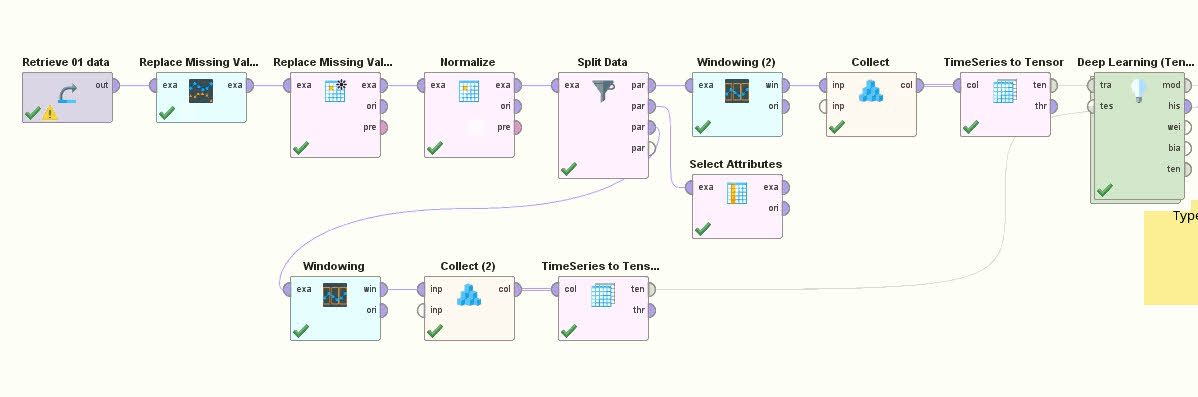
Evaluación
El entrenamiento y posterior evaluación de los modelos mencionados arrojó las siguientes medidas de exactitud:
| Modelo | Error Relativo |
|---|---|
| Decision Tree | 86% |
| Random Forest | 97% |
| Generalized Linear Model | 82% |
| LSTM | 77% |
Se observa experimentalmente que el desempeño de los modelos tradicionales es de mala calidad, induciendo a un error muy grande. Con el modelo LSTM se logró una mejora interesante, pero aún sigue siendo muy insuficiente para lograr un sistema confiable.
Conclusión
Se comprobó que pese a la mejora llevada a cabo por las redes neuronales, es extremadamente dificil predecir el movimiento de la bolsa de valores. Sin embargo el presente proyecto sirvió para integrar los diferentes pasos del análisis y desarrollo de sistema de machine learning y su necesario preprocesamiento de datos.
Se considera además que la red LSTM podría continuar siendo modificada para lograr mejores resultados, modificando la cantidad y configuración de las capas, y la cantidad de neuronas en cada una.
Referencias